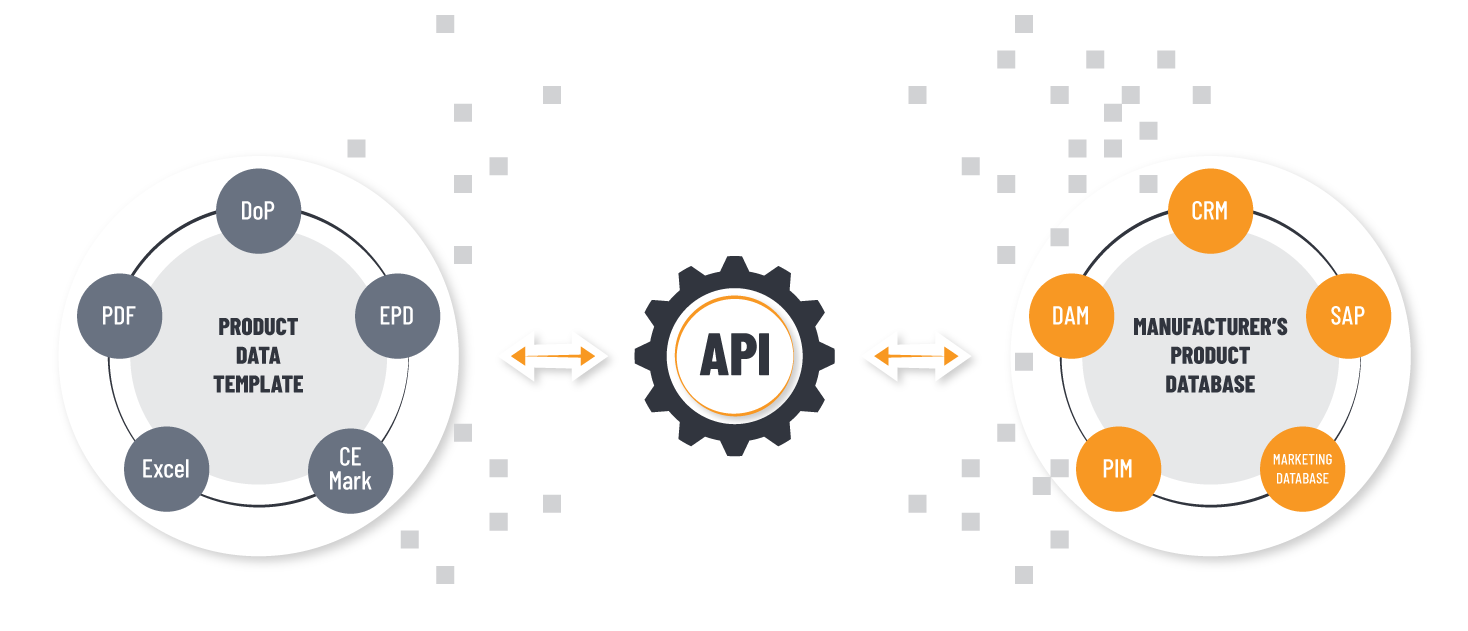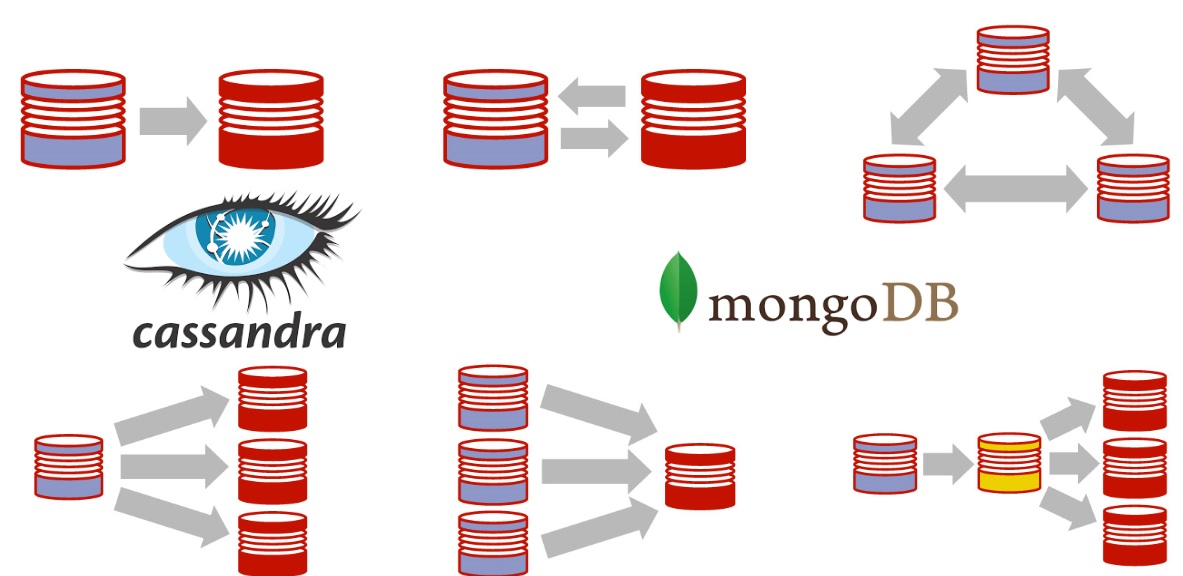
¿Qué sistema de base de datos NoSQL debemos usar para nuestra aplicación? ¿Cuándo debemos usar Cassandra? ¿Cuándo debemos usar MongoDB? ¿Cuál es mejor? No pretendo…
Bitácora Digital
¿Qué sistema de base de datos NoSQL debemos usar para nuestra aplicación? ¿Cuándo debemos usar Cassandra? ¿Cuándo debemos usar MongoDB? ¿Cuál es mejor? No pretendo…
Este tercer artículo abarca una breve introducción sobre como estructuramos el contenido (cuerpo) de nuestras respuestas HTTP (HTTP Body). ¿Qué es JSON? JSON (JavaScript Object…
Uno de mis alumnos me hizo esta pregunta: «Profesor, quiero desarrollarme como científico de datos, ¿Por donde empiezo?«. Mi respuesta inmediata fue: «Te felicito, que…
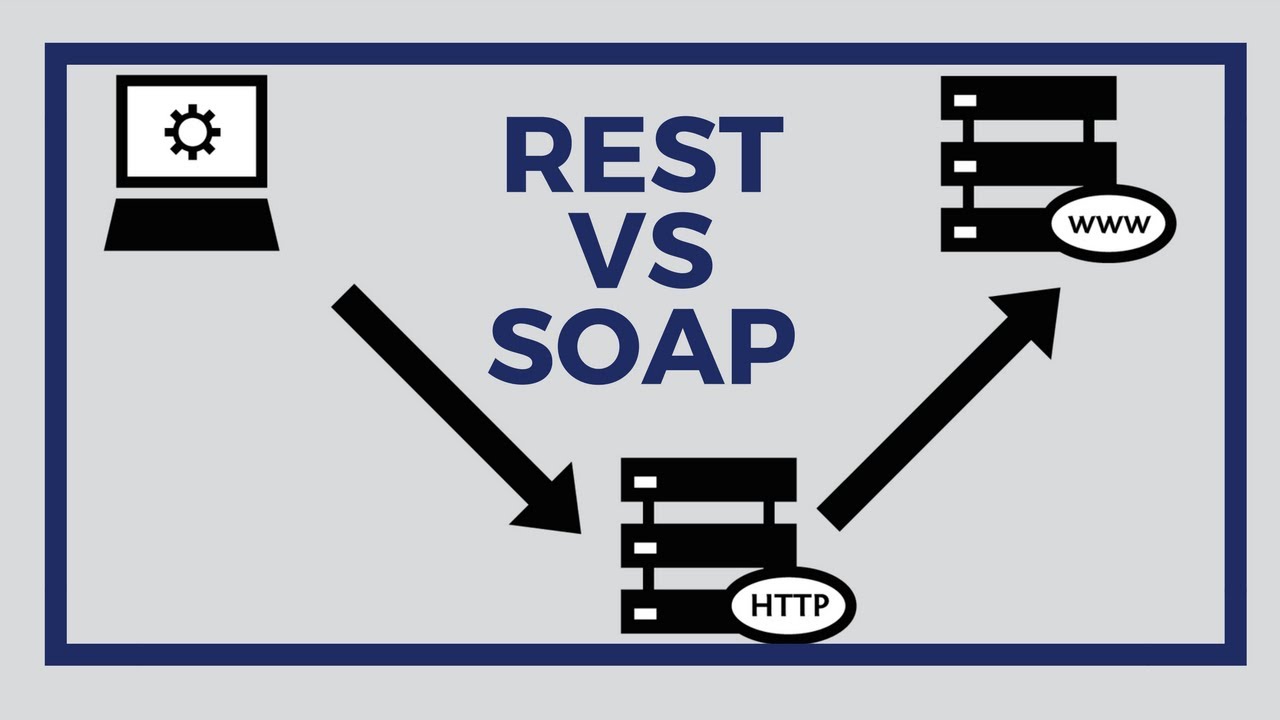
¿Cuál es mejor? SOAP, acrónimo de Simple Object Access Protocol, ha sido por muchos años el enfoque dominante en la Arquitectura Orientada a Servicios (SOA)…