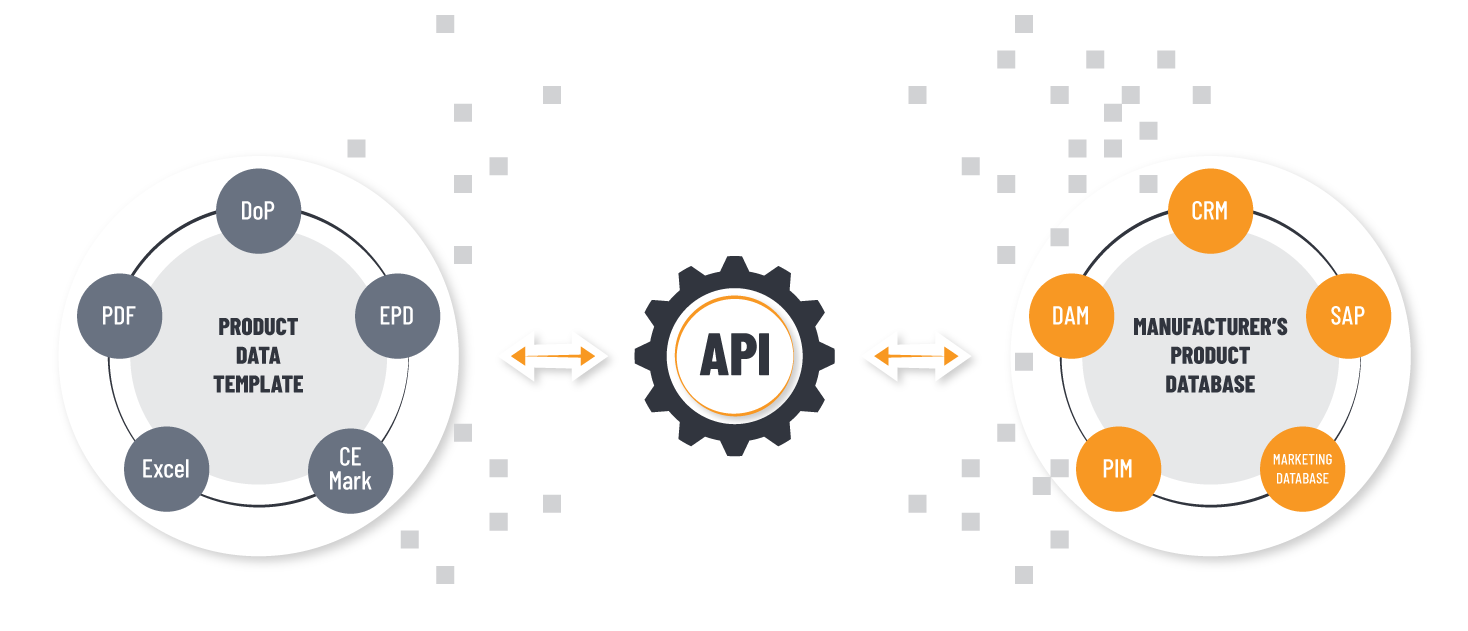
Este cuarto y último artículo hace un breve resumen sobre los distintos estándares aplicados en el diseño de una API HTTP para el intercambio de…
Bitácora Digital
Un HTTP Response, es la respuesta que devuelve un servidor web luego de recibir y procesar una solicitud HTTP (HTTP Request). La estructura del mensaje del HTTP Response es similar en formato al HTTP Request.
Este primer artículo abarca una breve introducción sobre las solicitudes HTTP (HTTP Requests). ¿Qué es una Solicitud HTTP? Creo que primero habría que definir que…
Esta publicación está influenciada sobre el libro Advanced Microservices, el cual describe estándares y buenas prácticas para el diseño de una API HTTP. Esta publicación se divide en 4 artículos.